Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads
Introduction
Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of our media encoding platform, Cosmos. Over the past 2.5 years, its usage has increased, and Timestone is now moreover the priority queueing engine valuables our general-purpose workflow orchestration engine (Conductor), and the scheduler for large-scale data pipelines (BDP Scheduler). All in all, millions of hair-trigger workflows within Netflix now spritz through Timestone on a daily basis.
Timestone clients can create queues, enqueue messages with user-defined deadlines and metadata, then dequeue these messages in an earliest-deadline-first (EDF) fashion. Filtering for EDF messages with criteria (e.g. “messages that vest to queue X and have metadata Y”) is moreover supported.
One of the things that make Timestone variegated from other priority queues is its support for a construct we undeniability exclusive queues — this is a ways to mark chunks of work as non-parallelizable, without requiring any locking or coordination on the consumer side; everything is taken superintendency of by the sectional queue in the background. We explain the concept in detail in the sections that follow.
Why Timestone
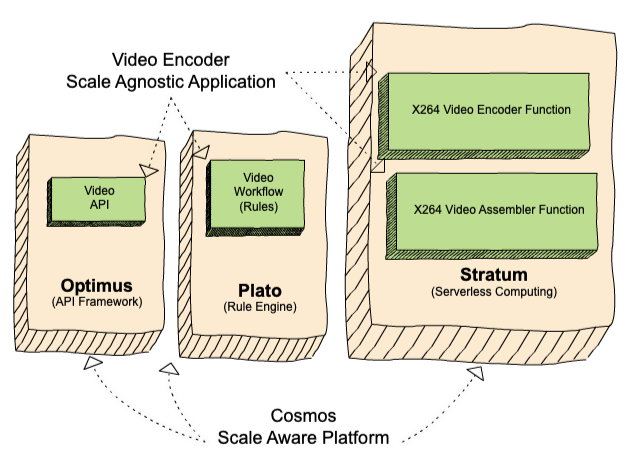
When designing the successor to Reloaded — our media encoding system — back in 2018 (see “Background” section in The Netflix Cosmos Platform), we needed a priority queueing system that would provide queues between the three components in Cosmos (Figure 1):
- the API framework (Optimus),
- the forward chaining rule engine (Plato), and
- the serverless computing layer (Stratum)
Some of the key requirements this priority queueing system would need to satisfy:
1. A message can only be prescribed to one worker at any given time. The work that tends to happen in Cosmos is resource-intensive, and can fan out to thousands of actions. Assume then, that there is replication lag between the replicas in our data store, and we present as dequeueable to worker B the message that was just dequeued by worker A via a variegated node. When we do that, we waste significant compute cycles. This requirement then throws sooner resulting solutions out of the window, and ways we want linearizable consistency at the queue level.
2. Allow for non-parallelizable work.
Given that Plato is continuously polling all workflow queues for increasingly work to execute —
While Plato is executing a workflow for a given project (a request for work on a given service) —
Then Plato should not be worldly-wise to dequeue spare requests for work for that project on that workflow. Otherwise Plato’s inference engine will evaluate the workflow prematurely, and may move the workflow to an incorrect state.
There exists then, a unrepealable type of work in Cosmos that should not be parallelizable, and the ask is for the queueing system to support this type of wangle pattern natively. This requirement gave lineage to the sectional queue concept. We explain how sectional queues work in Timestone in the“Key Concepts” section.
3. Allow for dequeueing and queue depth querying using filters (metadata key-value pairs)
4. Allow for the will-less megacosm of a queue upon message ingestion
5. Render a message dequeueable within a second of ingestion
We built Timestone considering we could not find an off-the-shelf solution that meets these requirements.
System Architecture
Timestone is a gRPC-based service. We use protocol buffers to pinpoint the interface of our service and the structure of our request and response messages. The system diagram for the using is shown in Figure 2.
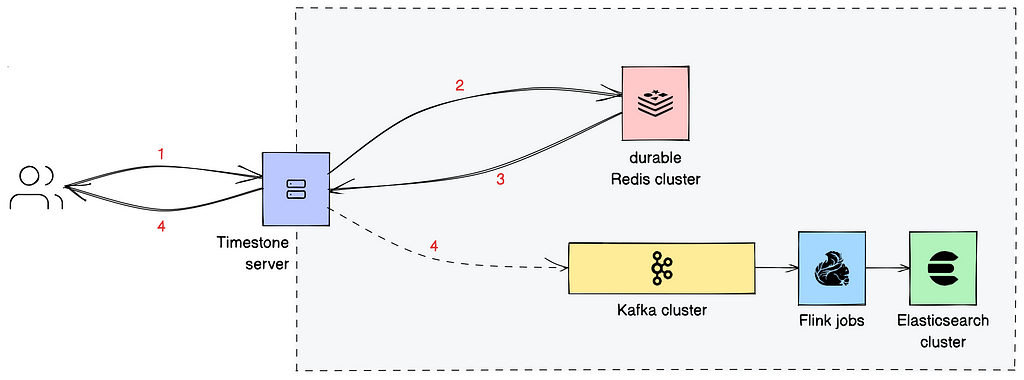
System of record
The system of record is a durable Redis cluster. Every write request (see Step 1 — note that this includes dequeue requests since they yo-yo the state of the queue) that reaches the cluster (Step 2) is persisted to a transaction log before a response is sent when to the server (Step 3).
Inside the database, we represent each queue with a sorted set where we rank message IDs (see “Message” section) equal to priority. We persist messages and queue configurations (see “Queues” section) in Redis as hashes. All data structures related to a queue — from the messages it contains to the in-memory secondary indexes needed to support dequeue-by-filter — are placed in the same Redis shard. We unzip this by having them share a worldwide prefix, specific to the queue in question. We then formulate this prefix as a Redis hash tag. Each message carries a payload (see “Message” section) that can weigh up to 32 KiB.
Almost all of the interactions between Timestone and Redis (see “Message States” section) are codified as Lua scripts. In most of these Lua scripts, we tend to update a number of data structures. Since Redis guarantees that each script is executed atomically, a successful script execution is guaranteed to leave the system in a resulting (in the ACID sense) state.
All API operations are queue-scoped. All API operations that modify state are idempotent.
Secondary indexes
For observability purposes, we capture information well-nigh incoming messages and their transition between states in two secondary indexes maintained in Elasticsearch. When we get a write response from Redis, we meantime (a) return the response to the client, and (b) convert this response into an event that we post to a Kafka cluster, as shown in Step 4. Two Flink jobs — one for each type of alphabetize we maintain — consume the events from the respective Kafka topics, and update the indexes in Elasticsearch.
One alphabetize (“current”) gives users a best-effort view into the current state of the system, while the other alphabetize (“historic”) gives users a weightier effort longitudinal view for messages, permitting them to trace the messages as they spritz through Timestone, and wordplay questions such as time spent in a state, and number of processing errors. We maintain a version counter for each message; every write operation increments that counter. We rely on that version counter to order the events in the historic index. Events are stored in the Elasticsearch cluster for a finite number of days.
Current Usage at Netflix
The system is dequeue heavy. We see 30K dequeue requests per second (RPS) with a P99 latency of 45ms. In comparison, we see 1.2K enqueue RPS at 25ms P99 latency. We regularly see 5K RPS enqueue bursts at 85ms P99 latency. 15B messages have been enqueued to Timestone since the whence of the year; these messages have been dequeued 400B times. Pending messages regularly reach 10M. Usage is expected to double next year, as we migrate the rest of Reloaded, our legacy media encoding system, to Cosmos.
Key Concepts
Message
A message carries an opaque payload, a user-defined priority (see “Priority” section), an optional (mandatory for sectional queues) set of metadata key-value pairs that can be used for filter-based dequeueing, and an optional invisibility duration. Any message that is placed into a queue can be dequeued a finite number of times. We undeniability these attempts; each dequeue invocation on a message decreases the attempts left on it.
Priority
The priority of a message is expressed as an integer value; the lower the value, the higher the priority. While an using is self-ruling to use whatever range they see fit, the norm is to use Unix timestamps in milliseconds (e.g. 1661990400000 for 9/1/2022 midnight UTC).
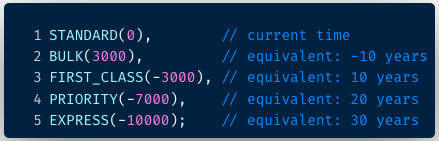
It is moreover entirely up to the using to pinpoint its own priority levels. For instance a streaming encoding pipeline within Cosmos uses mail priority classes, as shown in Figure 3. Messages belonging to the standard matriculation use the time of enqueue as their priority, while all other classes have their priority values adjusted in multiples of ∼10 years. The priority is set at the workflow rule level, but can be overridden if the request carries a studio tag, such as DAY_OF_BROADCAST.
Message States
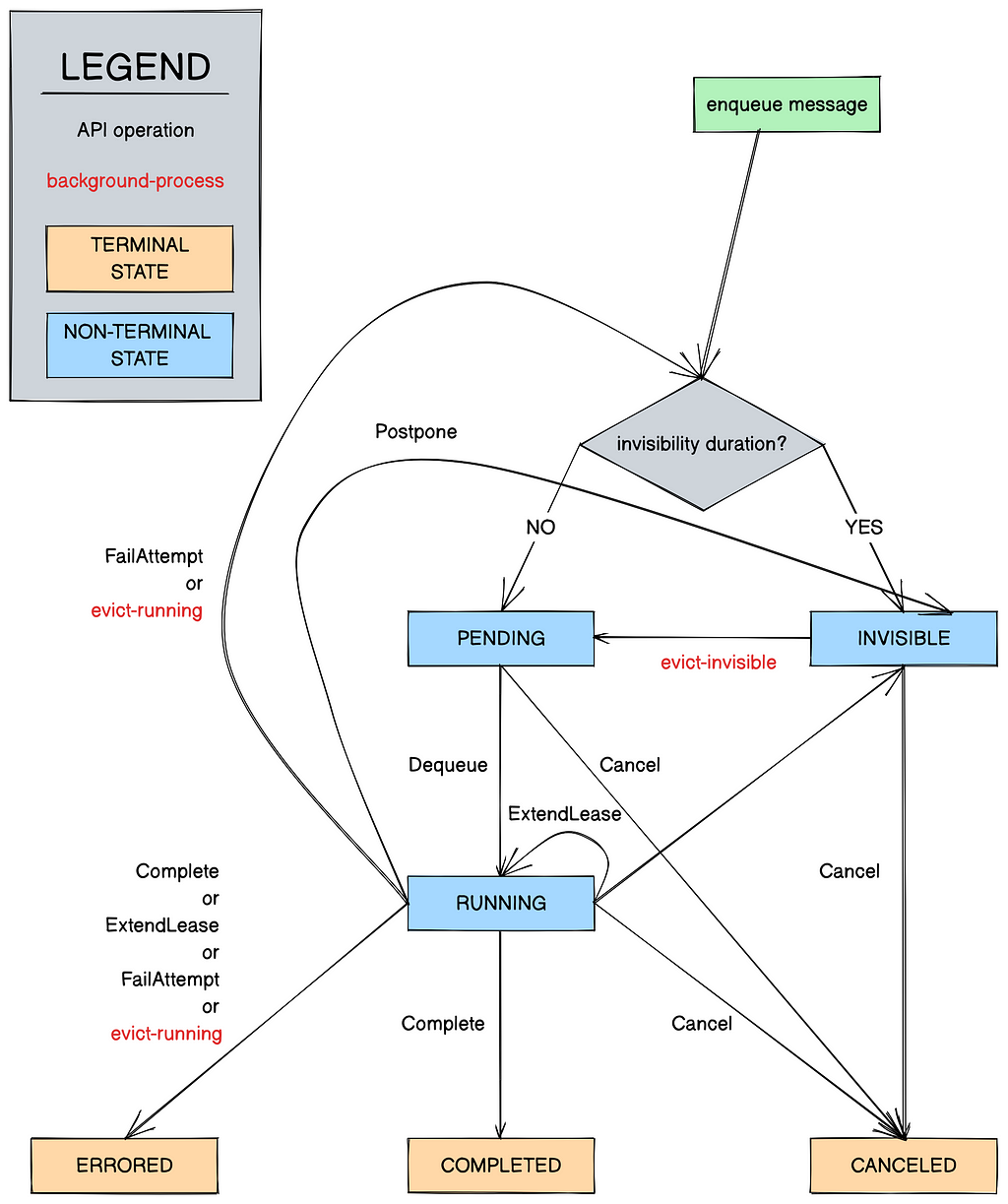
Within a queue, a Timestone message belongs to one of six states (Figure 4):
- invisible
- pending
- running
- completed
- canceled
- errored
In general, a message can be enqueued with or without invisibility, which makes the message invisible or pending respectively. Invisible messages wilt pending when their invisibility window elapses. A worker can dequeue a pending earliest-deadline-first message from a queue by specifying the value of time (lease duration) they will be processing it for. Dequeueing messages in batch is moreover supported. This moves the message to the running state. The same worker can then issue a well-constructed undeniability to Timestone within the allotted lease window to move the message to the completed state, or issue a lease extension undeniability if they want to maintain tenancy of the message. (A worker can moreover move a typically running message to the canceled state to signal it is no longer need for processing.) If none of these calls are issued on time, the message becomes dequeueable again, and this struggle on the message is spent. If there are no attempts left on the message, it is moved automatically to the errored state. The terminal states (completed, errored, and canceled) are garbage-collected periodically by a preliminaries process.
Messages can move states either when a worker invokes an API operation, or when Timestone runs its preliminaries processes (Figure 4, marked in red — these run periodically). Figure 4 shows the well-constructed state transition diagram.
Queues
All incoming messages are stored in queues. Within a queue, messages are sorted by their priority date. Timestone can host an wrong-headed number of user-created queues, and offers a set of API operations for queue management, all revolving virtually a queue configuration object. Data we store in this object includes the queue’s type (see rest of section), the lease elapsing that applies to dequeued messages, or the invisibility elapsing that applies to enqueued messages, the number of times a message can be dequeued, and whether enqueueing or dequeueing is temporarily blocked. Note that a message producer can override the default lease or invisibility elapsing by setting it at the message level during enqueue.
All queues in Timestone fall into two types, simple, and exclusive.
When an exclusive queue is created, it is associated with a user-defined exclusivity key — for example project. All messages posted to that queue must siphon this key in their metadata. For instance, a message with project=foo will be wonted into the queue; a message without the project key will not be. In this example, we undeniability foo, the value that corresponds to the exclusivity key, the message’s exclusivity value. The contract for sectional queues is that at any point in time, there can be only up to one consumer per exclusivity value. Therefore, if the project-based sectional queue in our example has two messages with the key-value pair project=foo in it, and one of them is once leased out to a worker, the other one is not dequeueable. This is depicted in Figure 5.
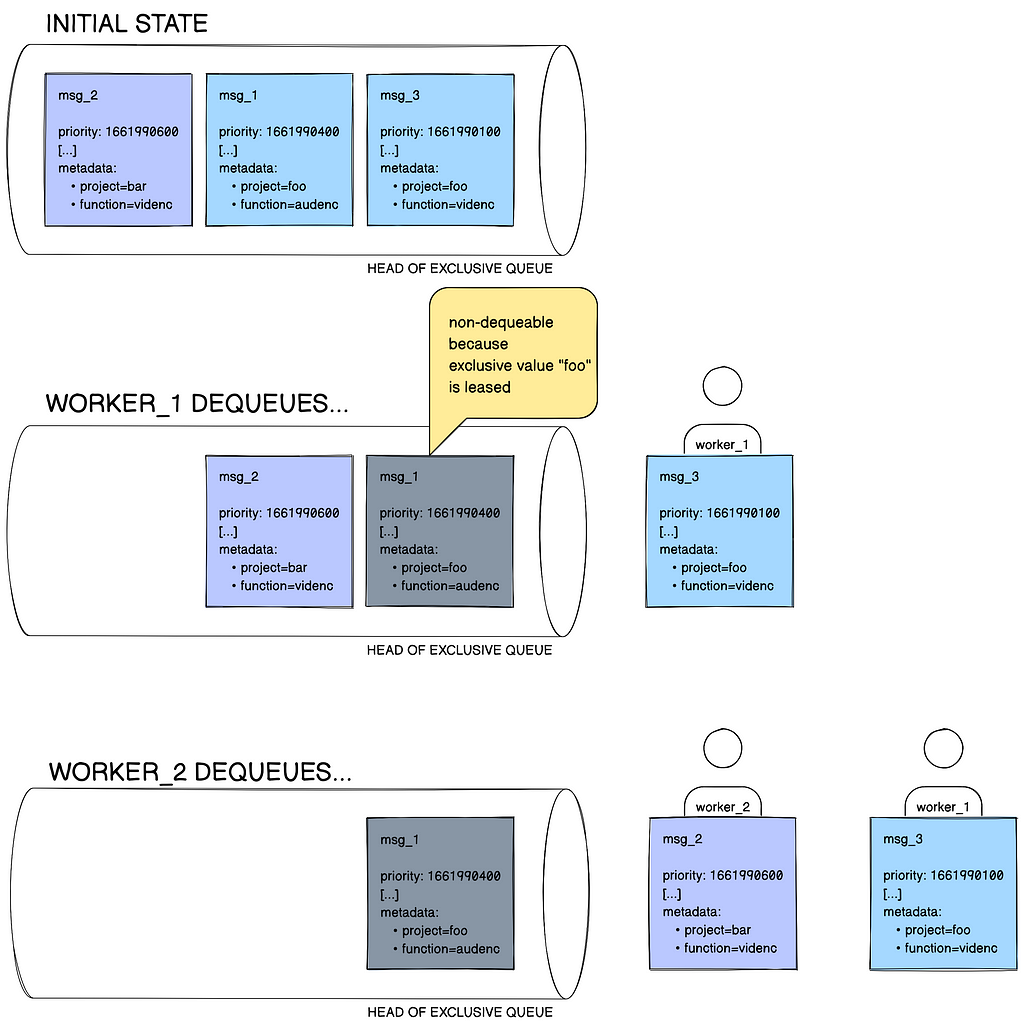
In a simple queue no such contract applies, and there is no tight coupling with message metadata keys. A simple queue works as your typical priority queue, simply ordering messages in an earliest-deadline-first fashion.
What We Are Working On
Some of the things we’re working on:
- As the the usage of Timestone within Cosmos grows, so does the need to support a range of queue depth queries. To solve this, we are towers a defended query service that uses a unshared query model.
- As noted whilom (see “System of record” section), a queue and its contents can only currently occupy one Redis shard. Hot queues however can grow big, esp. when compute topics is scarce. We want to support summarily large queues, which has us towers support for queue sharding.
- Messages can siphon up to 4 key-value pairs. We currently use all of these key-value pairs to populate the secondary indexes used during dequeue-by-filter. This operation is exponentially ramified both in terms of time and space (O(2^n)). We are switching to lexicographical ordering on sorted sets to waif the number of indexes by half, and handle metadata in a increasingly cost-efficient manner.
We may be tent our work on the whilom in follow-up posts. If these kinds of problems sound interesting to you, and if you like the challenges of towers distributed systems for the Netflix Content and Studio ecosystem at scale in general, you should consider joining us.
Acknowledgements
Poorna Reddy, Aravindan Ramkumar, Surafel Korse, Jiaofen Xu, Anoop Panicker, and Kishore Banala have unsalaried to this project. We thank Charles Zhao, Olof Johansson, Frank San Miguel, Dmitry Vasilyev, Prudhvi Chaganti, and the rest of the Cosmos team for their constructive feedback while developing and operating Timestone.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support… was originally published in Netflix TechBlog on Medium, where people are standing the conversation by highlighting and responding to this story.
Popular Workout Articles
-

-

-

Best New Netflix Series to Watch in India This Year
15 July, 2026 -








